FLI
2025-06-26: Finally, the complete version of this paper was published!
Read the announcement here.
2024-05-16: Our paper was accepted!
Read the announcement here.
Fast Linear Interpolation, in collaboration with Olivier Ruas, is a new data modeling approach which allows storing big amounts of data on constrained devices. It’s mainly been the work of Olivier, whom I helped to develop experimental apps.
It contains two contributions:
- FLI modeling part, which enables storing entire datasets on phones;
- Divide&Stay, which protects geolocation data on phones (FLI’s use-case)
Contents
FLI modeling
In this paper, we propose FLI, a new modeling approach enabling a big space gain with a low approximation error; please note that this applies only to temporal data streams (e.g. data indexed by time, i.e. accelerometer data).
FLI takes one argument as input, the value of the tolerated error, noted ε.
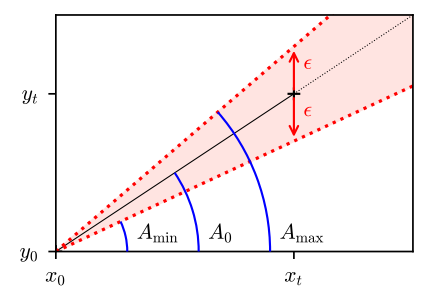 |
|---|
| Tolerated error ε, persisted model (x0, y0, A0) and in-memory (Amin, Amax) cone. |
Then, to insert new data, the model checks if newly-inserted point fits the current model by checking if it’s inside the error code (i.e. if point [xt,yt] is inside error code modeled by x0, Amin and Amax).
If it fits, Amin and Amax are updated; else, current model is saved, and a new one is created.
Performances benchmark
We check FLI’s storage capabilities by modeling two mobility datasets, PrivaMov and Cabspotting.
- PrivaMov (5GB) is modeled with 25MB (ε=0.001) → 99.95% gain
- Cabspotting size gain equals 21.02% (ε=0.001), due to traces lower density.
Use-case: location privacy protection
From geolocation data, an attacker can infer information such as place of living or work; some mechanisms, called location privacy protection mechanisms (LPPMs), aim at preventing sensitive data leaks by transforming datasets a bit, so that private information cannot be inferred anymore but for data to still be usable.
Using FLI, we assert privacy protection provided by a LPPM called Promesse, by running POI1 attacks on users’ phones directly.
State-of-the-art POI attack is POI-attack, it is however slow to run (1h runtime on desktop computer, and it’s obviously worse on mobile devices); we propose a new implementation, dubbed Divide & Stay (D&S), that computes POIs faster.
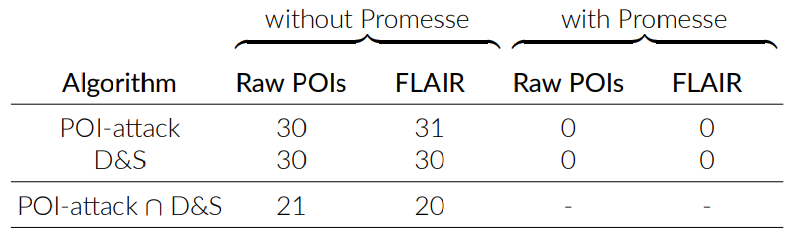 |
|---|
| Impact of FLI and D&S on the number of inferred POIs from user 0’s trace in Cabspotting. Thanks to FLI and D&S, Promesse succeeds to protect user privacy at the edge. |
We show here that using FLI to model data does not alter the quality of said data.
Communication material
I presented this work several times on different occasions, here is the material I used:
-
Points of Interest: geographical zones that infer sensitive data about their provider, such as place of living, work, shopping habits, political affiliations… ↩